
How to make a magnify glass
Here. you will learn a simple lesson to make a magnifying a glass, we use it to search tiny object in the big condition so it is a necessary.
Let's Start...
New File: Take a new file with any size as you want.
Text: Select Horizontal Type Tool (T key) set color ="black" and font size = "18", now write any text as I have done here.

Circle: Select Ellipse Tool (U key) and make a circle as given below.

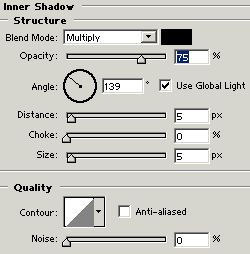
Inner Shadow: Go to Layer Menu > Layer Style > Inner Shadow and use settings.
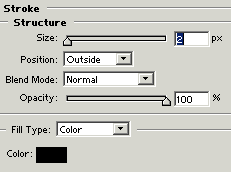
Stroke: Go to Layer Menu > Layer Style > Stroke and use use same settings.
This is you done.

Draw a shape: Select Pen tool (P key) and point by the mouse. If you are not able to make it, you can take help of Direct Selection Tool (A key) to change points location as similar here.

Handle: Now I am going to make magnifying handle, select Rectangle Tool (U key) and draw a rectangle shape then set it by transform (Ctr + T key).

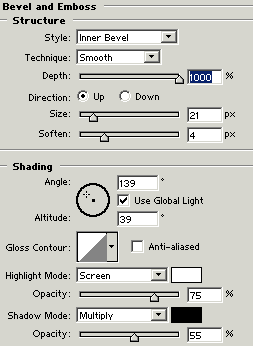
Bevel and Emboss: Go to Layer Menu > Layer Style > Bevel and Emboss and use settings as given below.
You will get it.

Increase Font Size: Make selection of the text
that is looking under the glass, increase the font size of text "18" to
"36".


Your image should be similar this.