
Introduction to Apache Spark Scala Shell
Getting started with the development of Apache Spark with the Apache Spark Scala Shell. This tutorial is for beginners in Apache Spark programming and covers the basics of using Spark Scala shell for writing Spark program in Scala programming language. Apache Spark provides Scala API for development of program for distributed processing of large data sets on the distributed Spark Cluster.
Apache Spark Scala Shell is utility program that comes with the Spark distribution which is used to run Spark Scala code in interactive mode. Developers can use this tool to test their scala program during development of application. This is easiest and fast method to test code during development. It saves a lot of development time as it maintains the Spark Context in shell session and developer can run scala code in bits and pieces during development. So, let's get started with the Apache Spark Scala shell and learn its basics.
What is Apache Spark Scala Shell?
The term Shell is used for a console based program which enables the users to interact with the operating system or core of any programming language. For example terminal (shell prompt) is used in Ubuntu to interact with the Ubuntu operating system through a set of commands. In case of Windows operating command prompt or power shell is used to interact with the windows operating system. Similarly Apache Spark comes with Scala Shell to interact with the Apache Spark server and run command(code) on the Spark server. You can write code and run it on the Spark cluster for processing the data in interactive mode and see the results. This is the best way to interactively develop program and see the processing results.
In this tutorial we will teach you Apache Spark Shell commands in step-by-step fashion with examples. We will explain you various commands to interact with the shell. If you have already not installed Apache Spark on your system then follow the tutorial Installing Apache Spark on Ubuntu 18.04 for installing it on your Ubuntu Operating system.
In this example you will learn the various ways to create RDD in Apache Spark in Scala Programming language. You will also learn to perform various operations like filter(), partitions(), cache(), count(), collect, etc. on the RDD object. We will create RDD from text file or with the help of parallelize() function of sc (SparkContext) instance. In future example in this tutorial series you will also learn to interact with the Hadoop File System (HDFS).
Apache Spark Shell comes with the auto complete feature which assists developers during coding/testing. You can type initial few letters of the object in the memory and the press TAB button, then shell will try to auto complete. You can activate the tab by running following command in pyspark shell:
import rlcompleter, readline
readline.parse_and_bind("tab: complete")
After this auto complete will start working in pyspark shell. The auto complete feature is very helpful when you are doing interactive programming in sparkshell.
There are 3 variant of spark shell for different programming languages:
- spark-shell for Scala
- pyspark for Python and
- sparkR for
Apache Spark supports Java, Scala, Python and R programming languages for development of program which can be executed distributed Spark cluster.
Getting Started with Spark with spark-shell
As explained earlier spark-shell is a tool for writing Spark program in Scala programming language. Open terminal in your Ubuntu operating system and run following command from the Apache Spark installation directory:
$ ./bin/spark-shell
This will open scala shell where you can write Spark code in Scala programming language:
root@deepak-VirtualBox:/home/deepak/spark-2.4.0-bin-hadoop2.7# ./bin/spark-shell
2018-11-19 21:02:18 WARN Utils:66 - Your hostname, deepak-VirtualBox
resolves to a loopback address: 127.0.1.1; using 10.0.2.15 instead (on interface enp0s3)
2018-11-19 21:02:18 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address
2018-11-19 21:02:18 WARN NativeCodeLoader:62 - Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://10.0.2.15:4040
Spark context available as 'sc' (master = local[*], app id = local-1542641545677).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Open your browser browse to http://localhost:4040/jobs/ in browser to view the "Spark shell application UI". Here you can view the complete details of job running on the Apache Spark Server. Here is the screen shot of "Spark shell application UI":
Here you can see the Stages, Storage, Environment and Executors of your running spark program.
The spark-shell is an extension of Scala REPL(command-line shell) which allows you to interactively execute programs. This shell is designed for the instantiation of SparkSession as spark (and SparkContext as sc) at the time of initialization of the shell. You can run the following commands to see the details of spark and sc variables.
scala> :type spark org.apache.spark.sql.SparkSession scala> :type sc org.apache.spark.SparkContext scala>
Creating RDDs in Scala Shell in Spark
Data Structures plays very important role in the programming language and in Apache Spark RDD is the fundamental Data Structure. The RDD stands for Resilient Distributed Datasets and it is in-memory distributed data in Spark Cluster cluster. In RDD data is divided into logical partitions and distributed over nodes in the Spark Cluster. The RDD was the first data structure which was introduced with the Apach Spark. RDD is immutable object and new RDD can be created by performing transformation on the RDD (Data). RDD data can't be modified one created.
Create RDD with parallelize() method
Here is example of creating RDD with the help of parallelize() method of sc object:
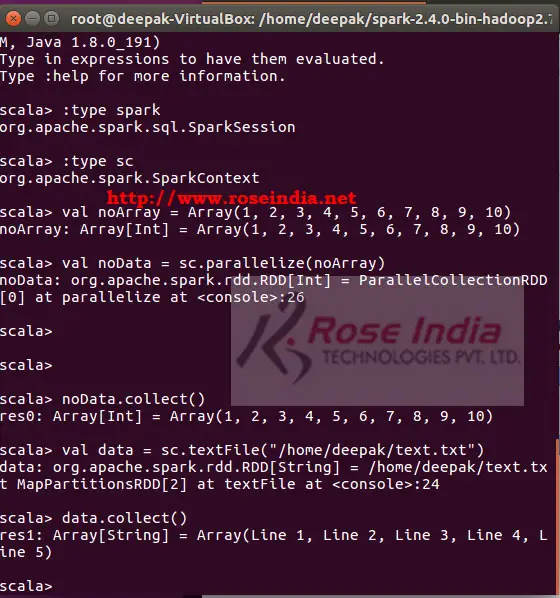
val noArray = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) val noData = sc.parallelize(noArray) noData.collect()
Here is the output of the program:
scala> val noArray = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) noArray: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> val noData = sc.parallelize(noArray) noData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at:26 scala> scala> scala> noData.collect() res0: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala>
Create RDD from file data
You can also read the text file and get the data in RDD. Create a text file (text.txt) with few lines in it:
Line 1 Line 2 Line 3 Line 4 Line 5
You can use following code to read file data into RDD:
val data = sc.textFile("/home/deepak/text.txt")
data.collect()
Here is the output of the program:
scala> val data = sc.textFile("/home/deepak/text.txt")
data: org.apache.spark.rdd.RDD[String] = /home/deepak/text.txt
MapPartitionsRDD[2] at textFile at :24
scala> data.collect()
res1: Array[String] = Array(Line 1, Line 2, Line 3, Line 4, Line 5)
Here is the screenshot of the spark shell:
You can view the executed jobs in the "Spark shell application UI" by opening http://localhost:4040/jobs/ in web browser:
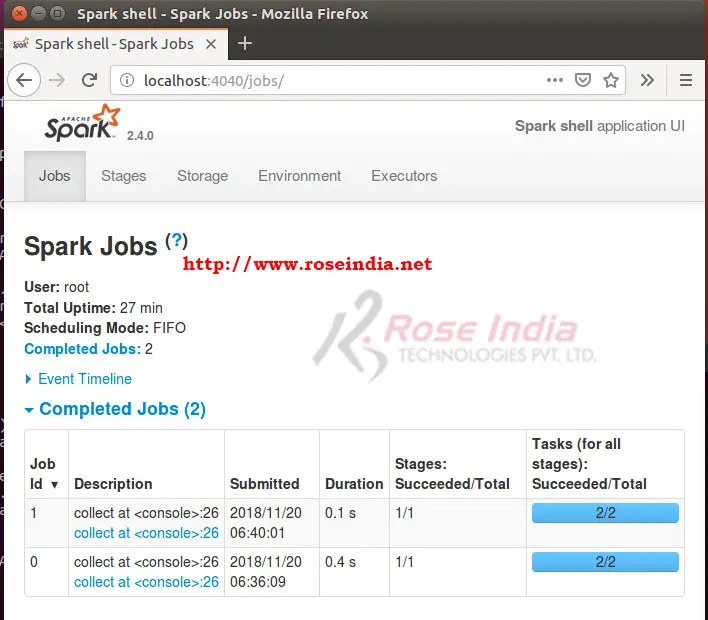
Here is the screen shot of Stages for all jobs:

Finally to quit from the Spark Scala Shell type: 0
scala> :q
Above command will close the object, sessions, context and come out from the shell.
In this section we learned the basics usage of Spark Scala shell and also understood the ways to create RDD.
Check Tutorials at: Apache Spark Framework programming tutorial. 1