
In this video tutorial I am going to introduce you with the Apache Spark Framework which is latest technology for processing Big Data.
Apache Spark is new Framework and it is top project at Apache Foundation. So, today we will learn about the Apache Spark Framework.
What is Spark Framework?
Apache Spark framework is next generation framework for Big Data processing and this framework is 100 times faster than Map Reduce for certain application.
Apache Spark framework is open source framework for Big Data processing and used to process large data sets. This framework brings fast processing to Big Data Environment.
This framework works with standalone and cluster mode. It can use the data in HDFS, Cassandra, HBase, Hive, Tachyon, and any Hadoop data source.
Application can be developed in Java, Scala, Python and R programming languages to develop application and run on Apache Spark Framework.
Following video tutorial introduces you with the Apache Spark Framework:
History of Apache Spark Framework?
Apache Spark Framework was started as research project at UC Berkeley AMPLab in 2009.
This project was open sourced in early 2010 and in 2013 this project was moved to Apache Software
Apache Software working on this project and the recent release of the project is Apache Spark 1.5.2 at the time of writing of this tutorial.
Over 4000 developers from 100 companies are contributing to this project.
This project is hosted on the community server the GitHub.
Apache Spark Framework is one of the top projects today.
Apache Spark Timeline:
� 2007: Dryad paper was published by Microsoft
� 2009: Spark is founded at U.C. Berkeley
� 2010: Spark was Open Sourced
� 2013: Project moved to Apache Software Foundation
� 2015: Apache Spark version 1.4 released
How Spark Framework works?
The Core fundamental of the Apache Spark framework is RDDs and it works as interface to you data. The RDDs stands for Resilient Distributed Dataset and it is Immutable, partitioned collection of records.
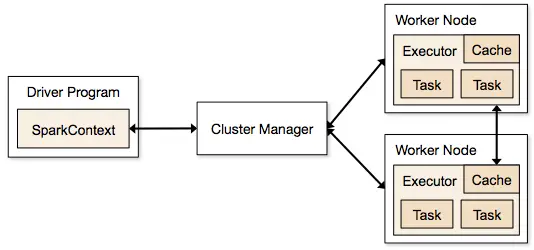
Apache Spark Framework distributes the work on the Worker Node and on the worker node data are ached in the memory for faster processing.
Features of Spark Framework
Apache Spark Framework is designed to work with the existing Hadoop clusters and provide faster processing.
Here are the features of Apache Spark Framework:
Hadoop Integration: Apache Spark works with existing Hadoop cluster and can work with already saved files in HDFS. 0
Spark?s Interactive Shell: Users can use the Spark Interactive shell to execute the commands using Scala language.
Spark?s Analytic Suite: It can be used for the analysis and large-scale graph processing.
Resilient Distributed Datasets (RDD?s): Apache Spark works with RDD?s and this is the primary data objects used in Spark. 1
Distributed Operators: Apache Spark Support MapReduce and many other operators.