
Install PySpark on Ubuntu - Learn to download, install and use PySpark on Ubuntu Operating System
In this tutorial we are going to install PySpark on the Ubuntu Operating system. Steps given here is applicable to all the versions of Ubunut including desktop and server operating systems. Installing PySpark is the first step in learning Spark Programming with Python programming language. Python is one of most popular object oriented, scripting, interpreted programming language these days used for writing many types of applications.
Apache Spark distribution comes with the API and interface to use the Spark features from Python programming language. Spark distribution comes with the pyspark shell which is used by developers to test their Spark program developed in Python programming (PySpark) language. Programmers can use PySpark to develop various machine learning and data processing applications which can be deployed on the distributed Spark cluster.
In this section we are going to download and installing following components to make things work:
1. Download and Install JDK 8 or above
2. Download and install Anaconda for python
3. Download and install Apache Spark
4. Configure Apache Spark
Let's go ahead with the installation process.
1. Download and Install JDK 8 or above
First of all we have to download and install JDK 8 or above on Ubuntu operating system. If JDK 8 is not installed you should follow our tutorial How to Install Oracle Java JDK 8 in Ubuntu 16.04?
You should check java by running following command:
deepak@deepak-VirtualBox:~$ java -version java version "1.8.0_171" Java(TM) SE Runtime Environment (build 1.8.0_171-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode) deepak@deepak-VirtualBox:~$
After the installation of JDK you can proceed with the installation of Anaconda on Ubuntu operating system.
2. Download and install Anaconda for python
Python 3.6 or above is required to run PySpark program and for this we should install Anaconda on Ubuntu operating System. Anaconda python comes with more than 1000 machine learning packages, so its very important distribution of Python for machine learning developers.
If Anaconda Python is not installed on your system check tutorials How to install Anaconda in Ubuntu?.
You should verify installation with typing following command on Linux terminal:
deepak@deepak-VirtualBox:~$ python --version Python 3.6.4 :: Anaconda, Inc. deepak@deepak-VirtualBox:~$
After installation of Python we can proceed with the installation of Spark.
3. Download and install Apache Spark
Now the next step is to download latest distribution of Spark. Visit the website https://spark.apache.org/downloads.html and there you will find the latest distribution of Spark framework. At the time of writing of this tutorial Spark framework was spark-2.3.0-bin-hadoop2.7.tgz.

Click on the spark-2.3.0-bin-hadoop2.7.tgz link to download spark.

You will get url to download, click on the full link as shown in above url. Now save the save the file on your computer as shown below:

create a directory spark with following command in your home.
mkdir spark
Move spark-2.3.0-bin-hadoop2.7.tgz in the spark directory:
deepak@deepak-VirtualBox:~$ mv ~/Downloads/spark-2.3.0-bin-hadoop2.7.tgz spark deepak@deepak-VirtualBox:~$ cd spark/ deepak@deepak-VirtualBox:~/spark$ ls spark-2.3.0-bin-hadoop2.7.tgz deepak@deepak-VirtualBox:~/spark$ deepak@deepak-VirtualBox:~/spark$ tar -xzvf spark-2.3.0-bin-hadoop2.7.tgz spark-2.3.0-bin-hadoop2.7/ spark-2.3.0-bin-hadoop2.7/jars/ spark-2.3.0-bin-hadoop2.7/jars/breeze-macros_2.11-0.13.2.jar spark-2.3.0-bin-hadoop2.7/jars/parquet-format-2.3.1.jar spark-2.3.0-bin-hadoop2.7/jars/hadoop-yarn-client-2.7.3.jar
After extracting the file go to bin directory of spark and run ./pyspark
It will open following pyspark shell:
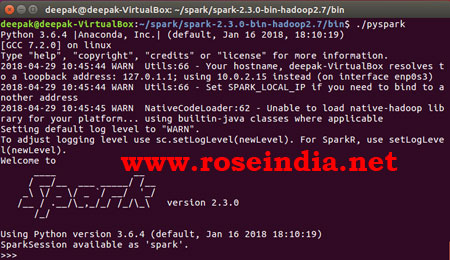
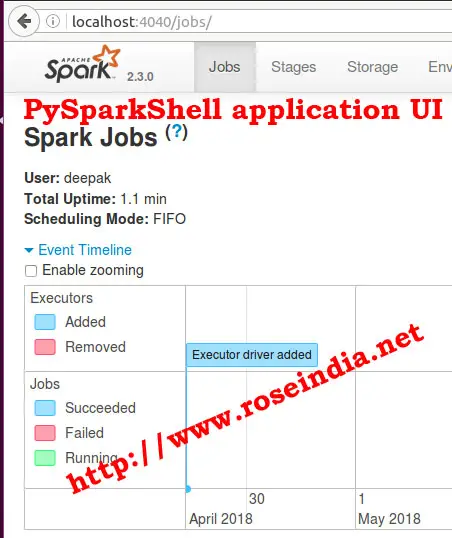
You can check the web UI in browser at localhost:4040
4. Configure Apache Spark
Now you should configure it in path so that it can be executed from anywhere. Open bash_profile file:
vi ~/.bash_profile
Add following entry:
export SPARK_HOME=~/spark/spark-2.3.0-bin-hadoop2.7/ export PATH="$SPARK_HOME/bin:$PATH"
Run the following command to update PATH variable in the current session:
source ~/.bash_profile
After next login you should be able to find pyspark command in path and it can be accessed from any directory.