
HTML Scrapping: How to extract HTML elements from a page?
In this tutorial we are going to teach you how to extract the HTML elements from a web page. Such activities are normal while developing a web scraping project. During web scraping you have to extract the data from the web page and for this many different programming languages are used. There are frameworks and API's in Java, Python and other programming languages. In this tutorial we are going to use the Python scrapy library to download the web page from the website and then extract the content of a HTML table. You can easily extend the code provided in this tutorial to develop advanced web scraping software.
What is web scrapping?
Web Scraping is the art of copying and pasting text out of web pages (often called web scraping) and collecting the relevant data. For example getting the product price data from various websites on a daily basis. There are many use cases and after scraping the data it is saved and used for further analytics. It can also be used to manipulate the data for some business purposes.
Web Scraping is most commonly used in writing web spiders. For example, a web crawler uses web scraping to load information from web pages, so that it can write a spider's logic.
There are many uses of web scraping in today?s internet world. Web scraping is one of the most useful, and under-appreciated, parts of web development. It's also one of the most complicated. Data retrieval Web Scraping is a very powerful way to get the information from the web page and then extract meaningful information from it.
What is a Web Scraper?
A Web Scraper is an automated tool designed to extract information from websites. It is usually used to find user data, content and other information about a website. These tools can be used only for getting the data from the publicly available websites and should not be used to scrap the authorised data. There are many commercial software for such purposes. Developers can also develop such applications in Python, Java or any other programming language.
A Web Scraper is designed to analyze a website and its content in order to extract information which would not usually be visible to the user in an easier and more rapid way than the user would ordinarily be able to do. Some examples of information you may be interested in are profile info (such as username, email, gender, date of birth, etc.), content, such as images, links, text or HTML code, and other information that is not normally viewable to the user. This information is usually referred to as a "Web Scraper". These days many companies are using Web Scraper for getting data from various websites for business or analytics use.
Python for Web scraping
Python is one of the most popular and easy to use programming languages to develop web scraping programs. There are many API?s and libraries available in Python for scraping the data from the website.
Python is a powerful programming language with a lot of API?s yet it's one of the easy programming languages to learn. Python comes with the support for creating programs using the object-oriented concepts. In the Python programming language classes and objects are significantly easier than other programming languages.
In this tutorial we will use the request and beautiful soup in Python for extracting HTML element from a page. We will extract the data from the html table present in a web page.
Install required libraries
First of all we have to install the required libraries in our Python installation. You can use the pip installer to install the package easily in your Python environment.
HTML Project page to be parsed
In this tutorial we are going to parse the following HTML project price page:
| Mobile Phone | Price |
| Honor 70 | $400 |
| Oppo Reno 8 | $390 |
| Oppo K10 Pro | $444 |
| Vivo Y22s | $260 |
| Vivo Y52t | $200 |
| Apple iPhone 14 Pro Max | $1600 |
| Apple iPhone 14 | $1599 |
| Apple iPhone 14 Pro | $2000 |
| Vivo iQOO Z6 Lite | $200 |
| Realme C33 | $177 |
Program will download above HTML page from the Internet and parse the data. Program will display the parsed data on the console. We will be parsing the HTML table element and extract the mobile price data from the web page.
You can view the HTML Page here.
Install Python libraries
For this tutorial we will use Python requests and BeautifulSoup libraries. Python request library will be used to download the data and BeautifulSoup library will be used to parse the HML table and extract the data from the page.
Here is the command to install these libraries into your Python environment:
pip install beautifulsoup4 pip install requests
Open the terminal and then run above two commands to install these libraries into your Python installation.
Python request library
The requests library in Python is powerful library for working with the HTTP servers and this library is used for making HTTP requests in Python. This library hides the complexity of HTTP protocol from the developers and makes it easy to write programs to interact with HTTP server quickly.
The requests API is used to make complex HTTP call and consume the data generated by HTTP server. This allows developers to focus on the development of business logic for application by hiding the complexity of HTTP protocol.
Python Beautiful Soup library
Beautiful Soup is a Python library which is very popular among developers for developing web scraping applications. This library comes with the API for parsing HTML and XML documents. In this tutorial we are using this library for parsing the HTML page and getting data from the table element.
Code for extracting HTML elements from a page
In the following code we are getting the HTML data and then extracting the data from the table present in the web page.
#import libraries
import requests
from bs4 import BeautifulSoup
page_url = "https://www.roseindia.net/d2/examples/html/productprice.htm"
r = requests.get(page_url)
soup = BeautifulSoup(r.text, 'html.parser')
table = soup.find_all('table')[0]
#print(table)
data = []
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele])
print(data)
Here is the screen shot of the program:
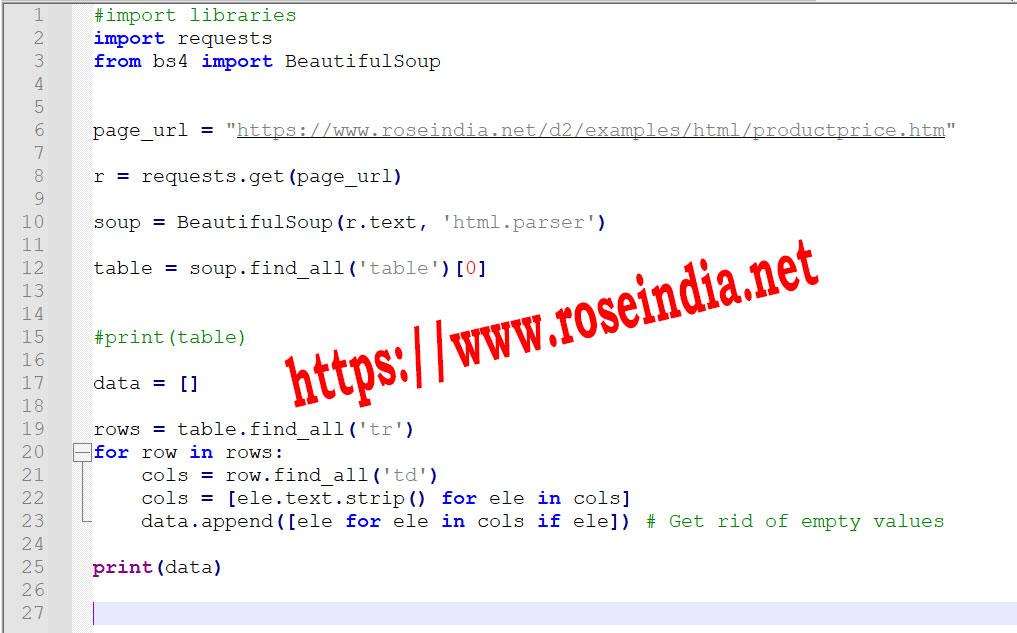
If you run the program you will get following output:
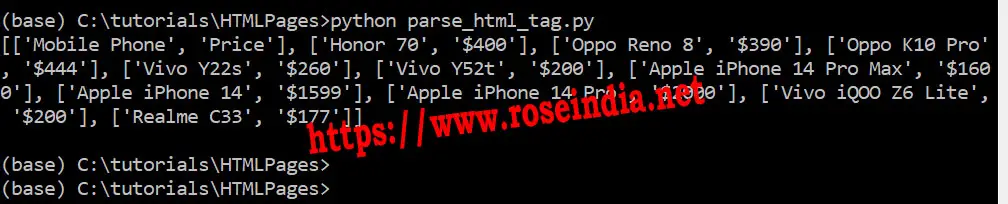
So, we have learned how to extract the html elements from the web page residing on the Internet. You can use Python requests and Beautiful Soup library for developing web scrapping applications.
If you are trying to scrape an Indian website it is best to send requests through Indian IPs to reduce the chance of getting blocked.
Related tutorials: