
Apache Solr 1.2 released
Welcome to Apache solr 1.2 ! To get started, I would
like to introduce Solr to you. Solr is a standalone enterprise full text search
engine. It is a high performance search server with a web-services like
API. It is based on on Lucene, with XML/HTTP and JSON APIs, hit highlighting, faceted search, caching, replication, and a Web administration interface.
It is written in Java5, and easily extensible through plugins written in Java. Documents are added to
a search collection via XML over HTTP. The collection is queried via HTTP to receive
an XML response (or alternately JSON, Python or Ruby text formats). More
precisely,
- Solr offers faceted searching, hit highlighting
- Optimized for High Volume Web Traffic
- Flexible and Adaptable with XML configuration
- Loose schema to define types and fields
- Extensive caching
- Extensible open architecture
- XML/HTTP Interfaces
- Web administration interface
- Index replication
- Advanced Full-Text Search Capabilities
- Extensible Plugin Architecture
- Flexible and Adaptable with XML configuration
- Scalability - Efficient Replication to other Solr Search Servers
Before proceeding any further, let me tell you about Lucene.
- Is is a full text search library.
- It searches for the documents via Indexsearcher
- Add documents to Index via IndexWriter
- Scoring: tf* idf* lengthNorm
Solr's history
Solr was first developed at CNET Networks. Solr steadily accumulated features and attracted a robust community of users, contributors, and
committers during its incubation period, which ended in January 2007. It has
been donated to the Apache Software Foundation in early 2006. Solr is now a subproject of
Lucene, which is Apache's Java-based full-text search engine library.
Now a days users expect high-quality search results like
Google that help them find what they're looking for quickly and easily. These
search engines are scalable, highly available, easy-to-maintain that doesn't cost a fortune to install.
Well Apache Solr is one of them. It is an open source, Lucene Java-based search server that is easy to incorporate into your Web applications.
Furthermore, it is impressive, it has a vibrant developer community that you can call on for help if you need it.
Architecture
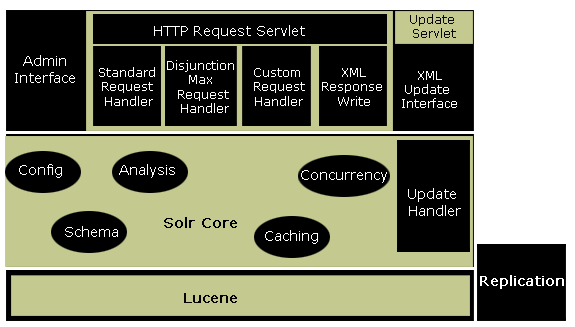
Solr Uses and extends the Lucene Search Library.
In Solr and Lucene, an index is built of one or more Documents. A Document consists of one or more Fields. A Field consists of a name, content, and metadata telling Solr how to handle the content. For instance, Fields can contain strings, numbers,
boolean, or dates, as well as any types you wish to add. A Field can be described using a number of options that tell Solr how to treat the content during indexing and searching.
- A Real Data Schema, with Numeric Types, Dynamic Fields, Unique Keys
- Powerful Extensions to the Lucene Query Language
- Support for Dynamic Faceted Browsing and Filtering
- Advanced, Configurable Text Analysis
- Highly Configurable and User Extensible Caching
- Performance Optimizations
- External Configuration via XML
- An Administration Interface
- Monitorable Logging
- Fast Incremental Updates and Snapshot Distribution
- XML and CSV/delimited-text update formats
Following are some of the features of Apache Solr:
Schema
- It can drive more intelligent processing
- Declarative Lucene Analyzer specification
- Defines the field types and fields of documents
- Explicit types eliminates the need for guessing types of fields
- Dynamic Fields enables on-the-fly addition of new fields
Query
- Advanced DisMax query parser for high relevancy results from user-entered queries
- Highlighted context snippets
- Faceted Searching based on unique field values and explicit queries
- HTTP interface with configurable response formats (XML/XSLT, JSON, Python, Ruby)
- Sort by any number of fields
- Constant scoring range and prefix queries - no idf, coord, or lengthNorm factors, and no restriction on the number of terms the query matches.
- Function Query - influence the score by a function of a field's numeric value or ordinal.
Core
- Correct handling of numeric types for both sorting and range queries
- Ability to control where docs with the sort field missing will be placed
- Batches updates and deletes for high performance
- Pluggable query handlers and extensible XML data format
- Document uniqueness enforcement based on unique key field
- User configurable commands triggered on index changes
- Searcher concurrency control
Caching
- Configurable Query Result, Filter, and Document cache instances
- Fast/small filter implementation
- User level caching with autowarming support
- Cache warming in background
* When a new searcher is opened, configurable searches are run against it in order to warm it up to avoid slow first hits. During warming, the current searcher handles live requests. - Autowarming in background
* The most recently accessed items in the caches of the current searcher are re-populated in the new searcher, enabing high cache hit rates across index/searcher changes. - Pluggable Cache implementations
Replication
- Efficient distribution of index parts that have changed via rsync transport
- Configurable distribution interval allows tradeoff between timeliness and cache utilization
- Pull strategy allows for easy addition of searchers
Admin Interface
- Text analysis debugger, showing result of every stage in an analyzer
- Web Query Interface w/ debugging output
* parsed query output
* Lucene explain() document score detailing
* explain score for documents outside of the requested range to debug why a given document wasn't ranked higher. - Comprehensive statistics on cache utilization, updates, and queries