
Getting started with Spark Framework: How to setup the development environment?
Apache Spark is the latest Big Data processing framework from Apache Foundation for processing the Data in Big Data environment. This framework is getting very popular and it is expected to be one of the most framework in the coming years.
In this tutorial I have provided you all the steps necessary to successfully create your development environment. Video tutorial teaches you how to configure all the necessary software to setup development environment for Apache Spark project.
Software required:
Following are the list of software you will need to setup the development environment with Apache Spark.
- JDK 8 or latest
- SBT - The interactive build tool
- Scala
- Hadoop runtime
- Maven build tool
- Spark Binary
- Eclipse IDE
In order to start the development using the Apache Spark framework you have to setup all the above software. Let's see one by one How to setup all these software to make your development environment.
Following is the video tutorial that "Getting Started with Apache Spark".
Step 1: Installing JDK or latest
Apache framework uses the latest features of JDK 8 such as steam, so first of all you have to setup the JDK 8 on your computer. If you have not already installed the JDK 8 on your computer check our tutorial: Installing JDK 8 on Windows 10 and configuring the settings.
Downloading and installing SBT tool
The SBT is interactive build tool, which you can use to runt the Scala taks in parallel from shell.
To download the SBT tool visit http://www.scala-sbt.org/0.13/tutorial/Installing-sbt-on-Windows.html as shown below:

Click on the ZIP or TGZ link and download will start quickly. Unzip the downloaded file in a directory and then add the following two values to your System environment variables:
a) Create SBT_HOME variable pointing to the SBT directory
b) Add %SBT_HOME%\bin to your system path variable
Step 2: Downloading and Installing Scala
Scala is programming language which compile into Java binary code and runs on JVM. You can download the Scala latest build by visiting the website http://www.scala-lang.org/download/ as shown below:
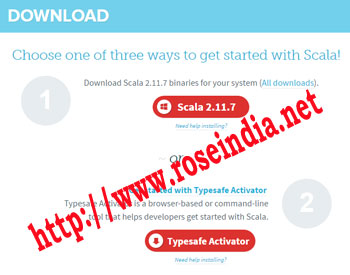
Click on the link and download the installer. After installer file is downloaded you can double click and install on your computer.
After the installation of Scala installer set following two variables in System environment settings:
a) Create SCALA_HOME=C:\Program Files (x86)\scala
b) Add %SCALA_HOME%\bin to your system path variable
Step 3: Installing Maven build tool
Maven build tool is required and you should install Maven build tool on your computer. If you don't know how to install check our tutorial - Downloading and installing Maven 3.
Step 4: Hadoop runtime
Spark framework required Hadoop runtime to work. So, download the Hadoop runtime from https://github.com/srccodes/hadoop-common-2.2.0-bin and then place the downloaded file in a directory where you would like to install Hadoop runtime.
Extract the dowloaded file and add following two settings in System environment:
a) Create HADOOP_HOME= directory of hadoop runtime 0
b) Add %HADOOP_HOME%\bin to your system path variable
Step 4: Spark Binary
The Apache Spark framework can be downloaded from its official website at http://spark.apache.org/downloads.html. Visit this website and select the following option: 1
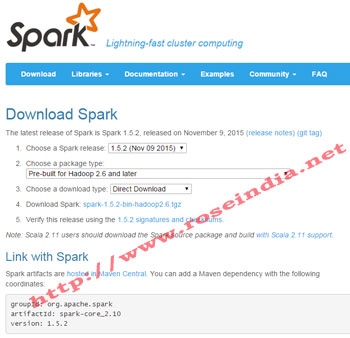
For the tutorial and usually for development purpose you can download Spark with Hadoop. To Spark framework with Hadoop select "Pre-built for Hadoop 2.6 and later" and "Direct Download" option as shown above. Then click on the spark-1.5.2-bin-hadoop2.6.tgz link to start download.
Downloading Spark without Hadoop 2
If you already have Hadoop and you want to use the existing Hadoop installation then use select the following option for downloading Spark without Hadoop:
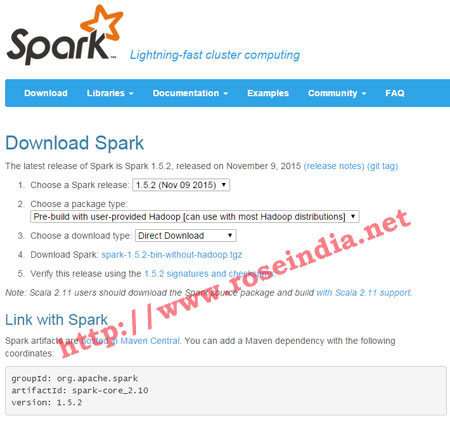
Select "Pre-build with user-provided Hadoop [can use with most Hadoop distributions]" and "Direct download" then click on the spark-xxx.bin-without-hadoop.tgz. 3
We are using the Spark with Hadoop for this tutorial so, once the download the completed move the file ( spark-1.5.2-bin-hadoop2.6.tgz) into a directory and extract it.
Now everything is ready to start the Spark server. Go to the bin directory of the spark and then run. To run the Spark with Hadoop go the bin directory of the extracted file and then type "spark-shell" on command prompt. This will start the Spark Framework with Hadoop as shown below:
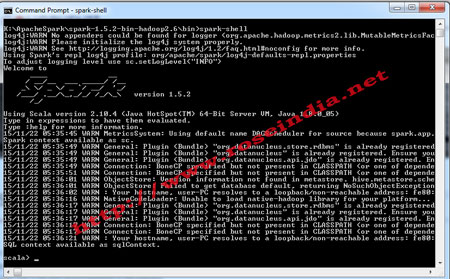 4
4
Here you can see the scala> promot which appears once Spark successfully. On the Scala console you can run the scala command. For example you can use the following command for printing the Hello Spark message.
scala> var msg = "Hello World"
scala> println(s" $msg") 5
If you the above command you will get the following output:
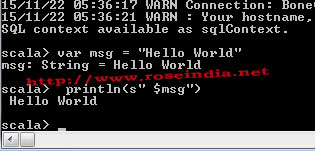
Here is the complete output of the program: 6
K:\ApacheSpark\spark-1.5.2-bin-hadoop2.6\bin>spark-shell
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.2
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_05)
Type in expressions to have them evaluated.
Type :help for more information.
15/11/22 05:35:45 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
Spark context available as sc.
15/11/22 05:35:49 WARN General: Plugin (Bundle) "org.datanucleus.store.rdbms" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/bin/../lib/datanucleus-rdbms-3.2.9.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar."
15/11/22 05:35:49 WARN General: Plugin (Bundle) "org.datanucleus" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/lib/datanucleus-core-3.2.10.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/bin/../lib/datanucleus-core-3.2.10.jar."
15/11/22 05:35:49 WARN General: Plugin (Bundle) "org.datanucleus.api.jdo" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/bin/../lib/datanucleus-api-jdo-3.2.6.jar."
15/11/22 05:35:49 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/22 05:35:51 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/22 05:36:01 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
15/11/22 05:36:01 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
15/11/22 05:36:02 WARN : Your hostname, user-PC resolves to a loopback/non-reachable address: fe80:0:0:0:0:5efe:c0a8:103%net6, but we couldn't find any external IP address!
15/11/22 05:36:16 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/11/22 05:36:17 WARN General: Plugin (Bundle) "org.datanucleus.store.rdbms" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/bin/../lib/datanucleus-rdbms-3.2.9.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar."
15/11/22 05:36:17 WARN General: Plugin (Bundle) "org.datanucleus" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/lib/datanucleus-core-3.2.10.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/bin/../lib/datanucleus-core-3.2.10.jar."
15/11/22 05:36:17 WARN General: Plugin (Bundle) "org.datanucleus.api.jdo" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/K:/ApacheSpark/spark-1.5.2-bin-hadoop2.6/bin/../lib/datanucleus-api-jdo-3.2.6.jar."
15/11/22 05:36:17 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/22 05:36:17 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/22 05:36:21 WARN : Your hostname, user-PC resolves to a loopback/non-reachable address: fe80:0:0:0:0:5efe:c0a8:103%net6, but we couldn't find any external IP address!
SQL context available as sqlContext.
scala> var msg = "Hello World"
msg: String = Hello World
scala> println(s" $msg")
Hello World
scala>
You can also access the Spark console at port no 4040, type http://localhost:4040/ in browser and you can see the console as shown below:
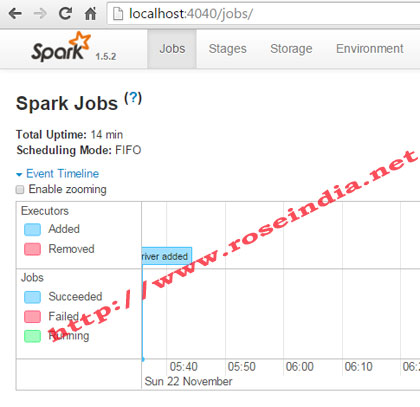
To stop the Apache Spark type exit on the scala console and this will shutdown the Apache Spark server. 7
Step 5: Eclipse IDE for development
Now you should download and install the Eclipse IDE if it is not installed on your computer. Check the tutorial Top 10 Features of Eclipse Mars if you don't know how to download and install Eclipse.
In this tutorial you leaned how to download, install and run Apache Spark Framework. 8
Check all tutorials of Spark Framework.