
| Chapter 4. Demonstrate understanding of database connectivity and messaging within IBM WebShpere Application Server | ||
|---|---|---|
| Prev | Part I. Exam Objectives | Next |
Data sources
As defined in the Sun JDBC 2.0 Standard Extension specification, data sources allow you to manage a pool of connections to a database. Using connection pools provides you with the following advantages:
It improves performance. Creating connections is expensive; a data source creates a connection as soon as it is instantiated.
It simplifies resource allocation. Resources are only allocated from the data sources, and not at arbitrary places in the code.
It simplifies connection calls. To get a connection in JDBC 1.0, you would need to call Class.forName() on the class name of the database driver, before making DriverManager calls.
Data sources work as follows:
When a servlet, EJB, or other client, wants to use a connection, it looks up a data source by name from a JNDI server.
The data source then returns a connection to the client.
If the data source has no more connections, it may ask the database manager for more connections (as long as it has not exceeded the maximum number of connections).
When the client has finished with the connection, it closes the connection.
The data source then returns the connection to the available pool.
You can configure data sources for WebSphere v4 and v5.x test environments and servers by using the data source page in the server editor.
Connection pooling
When accessing any database, the initial database connection is an expensive operation. Connection pooling enables administrators to establish a pool of database connections that applications can share on an application server. When connection pooling capabilities are used, performance improvements up to 20 times the normal results are realized. WebSphere Application Server does not support JDBC 3.0.
Each time a resource attempts to access a backend store (such as a database), the resource must connect to that data store. A connection requires resources to create, maintain, and then release the connection when it is no longer required.
The total data store overhead for an application is particularly high for Web-based applications because Web users connect and disconnect more frequently. In addition, user interactions are typically shorter. Often, more effort is spent connecting and disconnecting than is spent during the interactions. Also, because Internet requests can arrive from virtually anywhere, you can find usage volumes large and difficult to predict.
To help lessen these overhead problems, the WebSphere Application Server enables administrators to establish a pool of backend connections that applications can share on an application server. Connection pooling spreads the connection overhead across several user requests, thereby conserving resources for future requests.
WebSphere Application Server supports JDBC 2.0 Standard Extension APIs to provide support for connection pooling and connection reuse. The connection pool is used to direct JDBC calls within the application, as well as for enterprise beans using the database.
Each entity EJB transaction requires an additional connection to the database specifically to handle the transaction. Take this into account when calculating the number of data source connections.
On UNIX platforms, a separate DB2 process is created for each connection and these processes quickly affect performance on systems with low memory and cause errors.
If clones are used, one data pool exists for each clone. This is important when configuring the database maximum connections.
Benefits of connection pooling
Connection pooling can improve the response time of any application that requires connections, especially Web-based applications. When a user makes a request over the Web to a resource, the resource accesses a data source. With connection pooling, most user requests do not incur the overhead of creating a new connection because the data source can locate and use an existing connection from the pool of connections. When the request is satisfied and the response is returned to the user, the resource returns the connection to the connection pool for reuse. The overhead of a disconnect is avoided. Each user request incurs a fraction of the cost for connecting or disconnecting. After the initial resources are used to produce the connections in the pool, additional overhead is insignificant because the existing connections are reused.
When to use connection pooling
Use WebSphere connection pooling in an application that meets any of the following criteria:
It cannot tolerate the overhead of obtaining and releasing connections whenever a connection is used.
It requires Java Transaction API (JTA) transactions within WebSphere Application Server.
It needs to share connections among multiple users within the same transaction.
It needs to take advantage of product features for managing local transactions within the application server.
It does not manage the pooling of its own connections. 0
It does not manage the specifics of creating a connection, such as the database name, user name, or password.
How connections are pooled together
Whenever you configure a unique data source or connection factory, you are required to give it a unique Java Naming and Directory Interface (JNDI) name. This JNDI name, along with its configuration information, is used to create a connection pool. A separate connection pool exists for each configured data source or connection factory. 1
A separate instance of a given configured connection pool is created on each application server that uses that data source or connection factory. For example, if you run a three server cluster in which all of the servers use myDataSource, and myDataSource has a maximum connections setting of 10, then you can generate up to 30 connections (three servers times 10 connections). Be sure to consider this fact when determining how many connections to your backend resource you can support.
It is also important to note that when using connection sharing, it is only possible to share connections obtained from the same connection pool.
Connection pool settings 2
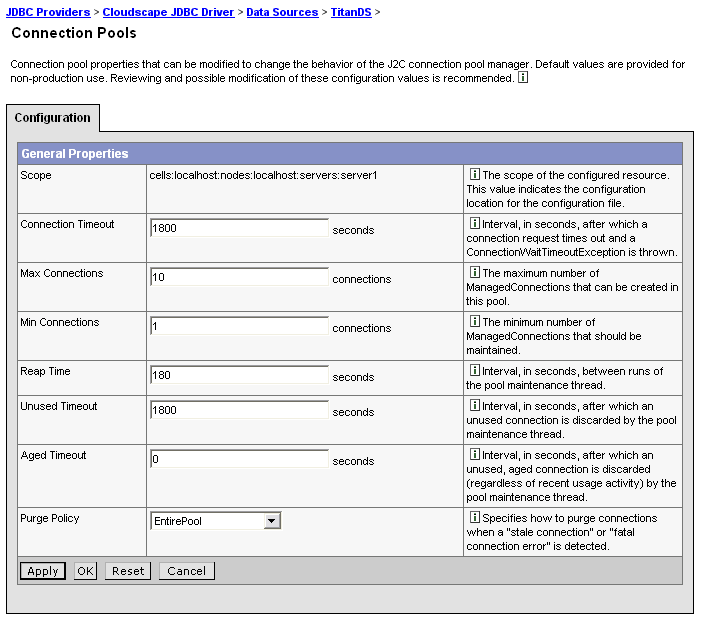
Use this page to configure connection pool settings.
This administrative console page is common to a range of resource types; for example, JDBC data sources and JMS queue connection factories. To view this page, the path depends on the type of resource, but generally you select an instance of the resource provider, then an instance of the resource type, then click Connection Pool. For example: click Resources > JDBC Providers > Cloudscape JDBC Driver > Data Sources > TitanDS > Connection Pool.
Connection Timeout 3
Specifies the interval, in seconds, after which a connection request times out and a ConnectionWaitTimeoutException is thrown.
The wait is necessary when the maximum value of connections (Max Connections) to a particular connection pool is reached . For example, if Connection Timeout is set to 300 and the maximum number of connections is reached, the Pool Manager waits for 300 seconds for an available physical connection. If a physical connection is not available within this time, the Pool Manager throws a ConnectionWaitTimeoutException. It usually does not make sense to retry the getConnection() method, because if a longer wait time is required, you should set the Connection Timeout setting to a higher value. Therefore, if this exception is caught by the application, the administrator should review the expected usage of the application and tune the connection pool and the database accordingly.
If Connection Timeout is set to 0, the Pool Manager waits as long as necessary until a connection is allocated (which happens when the number of connections falls below the value of Max Connections). 4
If Max Connections is set to 0, which enables an infinite number of physical connections, then the Connection Timeout value is ignored.
Max Connections
Specifies the maximum number of physical connections that you can create in this pool. 5
These are the physical connections to the backend resource. Once this number is reached, no new physical connections are created and the requester waits until a physical connection that is currently in use returns to the pool, or a ConnectionWaitTimeoutException is thrown.
For example, if the Max Connections value is set to 5, and there are five physical connections in use, the pool manager waits for the amount of time specified in Connection Timeout for a physical connection to become free.
If Max Connections is set to 0, the Connection Timeout value is ignored. 6
For better performance, set the value for the connection pool lower than the value for the Max Connections option in the Web container. Lower settings, such as 10-30 connections, perform better than higher settings, such as 100.
If clones are used, one data pool exists for each clone. Knowing the number of data pools is important when configuring the database maximum connections.
You can use the Tivoli Performance Viewer to find the optimal number of connections in a pool. If the number of concurrent waiters is greater than 0, but the CPU load is not close to 100%, consider increasing the connection pool size. If the Percent Used value is consistently low under normal workload, consider decreasing the number of connections in the pool. 7
Min Connections
Specifies the minimum number of physical connections to maintain.
Until this number is reached, the pool maintenance thread does not discard physical connections. However, no attempt is made to bring the number of connections up to this number. If you set a value for Aged Timeout, the minimum is not maintained. All connections with an expired age are discarded. 8
For example if the Min Connections value is set to 3, and one physical connection is created, the Unused Timeout thread does not discard that connection. By the same token, the thread does not automatically create two additional physical connections to reach the Min Connections setting.
Reap Time
Specifies the interval, in seconds, between runs of the pool maintenance thread. 9
For example, if Reap Time is set to 60, the pool maintenance thread runs every 60 seconds. The Reap Time interval affects the accuracy of the Unused Timeout and Aged Timeout settings. The smaller the interval, the greater the accuracy. If the pool maintenance thread is enabled, set the Reap Time value less than the values of Unused Timeout and Aged Timeout. When the pool maintenance thread runs, it discards any connections remaining unused for longer than the time value specified in Unused Timeout, until it reaches the number of connections specified in Min Connections. The pool maintenance thread also discards any connections that remain active longer than the time value specified in Aged Timeout.
The Reap Time interval also affects performance. Smaller intervals mean that the pool maintenance thread runs more often and degrades performance.
To disable the pool maintenance thread set Reap Time to 0, or set both Unused Timeout and Aged Timeout to 0. The recommended way to disable the pool maintenance thread is to set Reap Time to 0, in which case Unused Timeout and Aged Timeout are ignored. However, if Unused Timeout and Aged Timeout are set to 0, the pool maintenance thread runs, but only physical connections which timeout due to non-zero timeout values are discarded. 0
Unused Timeout
Specifies the interval in seconds after which an unused or idle connection is discarded.
Set the Unused Timeout value higher than the Reap Timeout value for optimal performance. Unused physical connections are only discarded if the current number of connections not in use exceeds the Min Connections setting. For example, if the unused timeout value is set to 120, and the pool maintenance thread is enabled (Reap Time is not 0), any physical connection that remains unused for two minutes is discarded. Note that accuracy of this timeout, as well as performance, is affected by the Reap Time value. See Reap Time for more information. 1
Aged Timeout
Specifies the interval in seconds before a physical connection is discarded.
Setting Aged Timeout to 0 supports active physical connections remaining in the pool indefinitely. Set the Aged Timeout value higher than the Reap Timeout value for optimal performance. For example, if the Aged Timeout value is set to 1200, and the Reap Time value is not 0, any physical connection that remains in existence for 1200 seconds (20 minutes) is discarded from the pool. The only exception is if the connection is involved in a transaction when the aged timeout is reached. If it is the connection is closed immediately after the transaction completes. 2
Note that accuracy of this timeout, as well as performance, are affected by the Reap Time value. See Reap Time for more information.
Purge Policy
Specifies how to purge connections when a stale connection or fatal connection error is detected. 3
Valid values are EntirePool and FailingConnectionOnly. JCA data sources can have either option. WebSphere Version 4.0 data sources always have a purge policy of EntirePool.
Data access beans
Data access beans provide a rich set of features and function, while hiding much of the complexity associated with accessing relational databases. 4
They are Java classes written to the JavaBeans Specification.
You can use the data access beans in JavaBeans-compliant tools, such as the IBM WebSphere Studio Application Developer (WSAD). Because the data access beans are also Java classes, you can use them like ordinary classes.
The data access beans (in the package com.ibm.db) offer the following capabilities: 5
Caching query results
You can retrieve SQL query results all at once and place them in a cache. Programs using the result set can move forward and backward through the cache or jump directly to any result row in the cache.
For large result sets, the data access beans provide ways to retrieve and manage packets, subsets of the complete result set. 6
Updating through result cache
Programs can use standard Java statements (rather than SQL statements) to change, add, or delete rows in the result cache. You can propagate changes to the cache in the underlying relational table.
Querying parameter support 7
The base SQL query is defined as a Java String, with parameters replacing some of the actual values. When the query runs, the data access beans provide a way to replace the parameters with values made available at run time. Default mappings for common data types are provided, but you can specify whatever your Java program and database require.
Supporting metadata
A StatementMetaData object contains the base SQL query. Information about the query (metadata) enables the object to pass parameters into the query as Java data types. 8
Metadata in the object maps Java data types to SQL data types (as well as the reverse). When the query runs, the Java-datatyped parameters are automatically converted to SQL data types as specified in the metadata mapping.
When results return, the metadata object automatically converts SQL data types back into the Java data types specified in the metadata mapping.
Example: Using data access beans in Version 5.0. DBSelect class allows you to execute a query and use its result set in a bean which exposes JDBC 2.0 RowSet functionality and adds its own useful functions for managing a RowSet. 9
package com.titan.access;
import java.sql.SQLException;
import com.ibm.db.beans.DBSelect;
public class DBSelectExample {
public static void main(String[] args) {
DBSelect select = new DBSelect();
try {
// Set database connection information
select.setDriverName("com.ibm.db2j.jdbc.DB2jDriver");
select.setUrl("jdbc:db2j:c:\\titandb");
// Specify the SQL statement to be executed
select.setCommand("SELECT * FROM MZ.SHIP");
// Execute the statement and retrieve the result set into the cache
select.execute();
// If result set is not empty
if (select.onRow()) {
do {
// display columns of result set
System.out.println(select.getColumnAsString(1));
System.out.println(select.getColumnAsString(2));
System.out.println(select.getColumnAsString(3));
System.out.println(select.getColumnAsString(4));
} while (select.next());
}
// Release the JDBC resources and close the connection
select.close();
} catch (SQLException ex) {
ex.printStackTrace();
}
}
}
Output in program console:
1 Nordic Prince 5000.00 300 2 Bohemian Rhapsody 6000.00 400
Visit http://java.boot.by for the updates.
| Prev | Up | Next |
| Implement mechanisms which support loose coupling between clients and components | Home | Interact with connection pools to obtain and release connections |